langgraph - Reducers, MapReduce, 'Send' API, MoA
Reference
Langgraph Reducers: 분산처리의 MapReduce의 관점에서 이해하기
분산 처리 시스템의 대표적인 패턴인 MapReduce와 Langgraph의 Reducers는 동일한 처리 패턴을 공유합니다. 두 시스템 모두 “큰 작업을 작은 단위로 나누어 병렬 처리한 후(Map), 결과를 다시 하나로 합치는(Reduce)” 방식으로 동작합니다.
MapReduce의 동작 방식:
- Map 단계: 큰 데이터를 작은 단위로 나누어 분배 (Fan-out)
- 병렬 처리: 각 작은 단위를 독립적으로 처리
- Reduce 단계: 처리된 결과들을 의미있게 통합 (Fan-in)
Langgraph Reducers의 동작 방식:
- Map 단계: 하나의 작업을 여러 Node로 분할 (Fan-out)
- 병렬 처리: 각 Node에서 독립적으로 상태 업데이트
- Reduce 단계: 업데이트된 상태들을 일관성 있게 통합 (Fan-in)
실제 예시: 채팅 애플리케이션에서의 MapReduce 패턴
채팅 애플리케이션에서 여러 메시지를 동시에 처리하는 예시를 통해 Langgraph Reducers의 MapReduce 패턴을 살펴보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from typing import Annotated
from operator import add
from typing_extensions import TypedDict
class ChatState(TypedDict):
user_name: str # 기본 리듀서: 덮어쓰기
message_list: Annotated[list[str], add] # 커스텀 리듀서: 리스트 확장 (Reduce 동작)
# Map 단계: 독립적인 노드들로 작업 분할
def add_message_node1(state: ChatState):
return {"message_list": ["Hello from node 1!"]}
def add_message_node2(state: ChatState):
return {"message_list": ["Hello from node 2!"]}
# Reduce 단계: add 리듀서를 통한 결과 통합
# message_list의 Annotated[list[str], add]가 여러 노드의 결과를 하나의 리스트로 통합
실행 과정을 보면:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 1. 초기 상태
initial_state = {
"user_name": "Anonymous",
"message_list": []
}
# 2. Map 단계: 메시지 노드들의 병렬 실행
# add_message_node1과 add_message_node2가 독립적으로 실행됨
# 3. Reduce 단계: 결과 통합
{
"user_name": "John",
"message_list": [
"Hello from node 1!",
"Hello from node 2!"
] # add 리듀서가 각 노드의 결과를 하나의 리스트로 통합
}
Send API: MapReduce 패턴의 효율적인 구현
Langgraph에서 MapReduce의 대표적인 예시는 바로 “복수 Node의 State update를 parallel하게 수행하는 것”입니다. Langgraph는 이러한 작업을 손쉽게 수행하도록 Send API를 제공합니다. MAP ‘이전’ 노드와 ‘이후’ Fan-out(Mapped, 펼쳐 나뉘어 진)된 노드들을 Send API로 conditional_edge로 연결해주면 됩니다.

“최고의 농담 선택하기” 시스템을 예로 들어보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
from langgraph.types import Send
# Map 단계: 하나의 주제를 여러 소재로 분할하여 각각 농담 생성
def continue_to_jokes(state: OverallState):
# Fan-out: 각 소재별로 독립적인 농담 생성 작업 분배
return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]
# Reduce 단계: 생성된 농담들 중 최고의 농담 선택
def select_best_joke(jokes: List[str]) -> str:
# Fan-in: 여러 농담들을 평가하여 하나의 최고 농담 선택
return find_best(jokes)
이 예시에서:
- Map 단계: “동물”이라는 하나의 주제가 여러 소재(사자, 코끼리, 타조)로 분할됨
- 병렬 처리: 각 소재별로 독립적으로 농담이 생성됨
- Reduce 단계: 생성된 모든 농담들 중에서 최고의 농담이 선택됨
MoA(Mixture of Agents): 실제 응용 사례
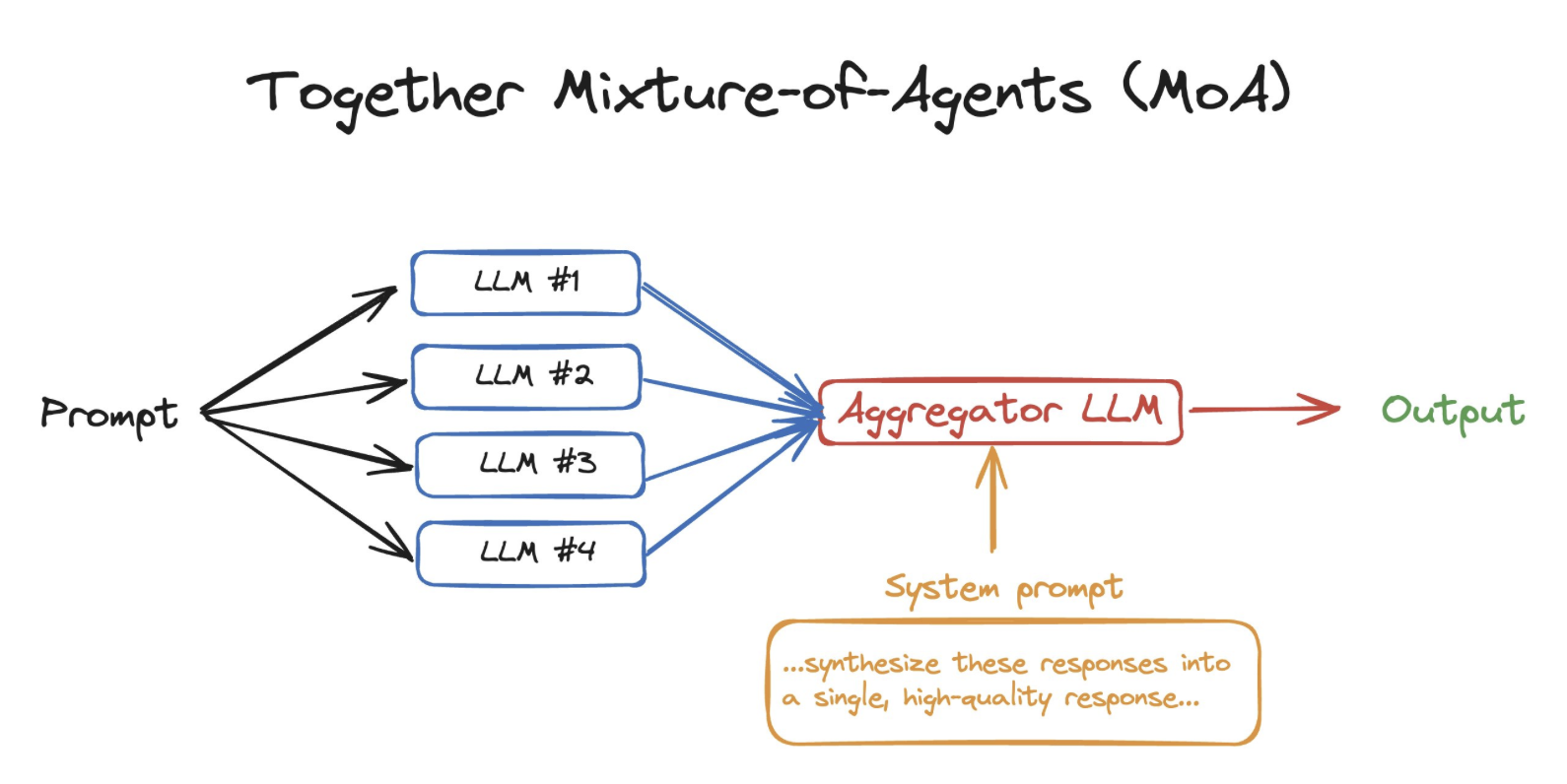
최근 제안된 “Mixture-of-Agents(2024)”는 Langgraph의 MapReduce 패턴을 활용한 좋은 예시입니다.
- Map 단계: 하나의 작업을 여러 LLM에게 분배
- 병렬 처리: 각 LLM이 독립적으로 답변 생성
- Reduce 단계: 생성된 답변들을 종합하여 최종 답변 도출
이러한 MapReduce 패턴을 Langgraph의 Send API를 통해 효율적으로 구현할 수 있습니다.
This post is licensed under CC BY 4.0 by the author.