Voice AI Agent (1) 파이프라인 전체 구조
들어가며
집에 SKT에서 만든 NUGU가 있습니다. 앱과 연결돼있어서 매일 아침 루틴도 설정해 알람이나 스케줄에 맞춰 라디오 요약도 재생하도록 할 수 있습니다. 그리고 무엇보다도 음성으로 대화할 수 있기도 합니다.
음 그런데 NUGU에게 말을 걸어보면, 내가 말을 멈춘 순간부터 답이 들려오기까지 아주 짧은 침묵이 있습니다. 저는 그동안 이 침묵을 별생각 없이 흘려보냈는데, 막상 음성 에이전트를 직접 만들어 보니 그 짧은 틈 안에서 꽤 많은 일이 벌어지고 있었습니다.
마이크로 들어온 소리를 텍스트로 바꾸고, 사용자가 말을 정말 끝냈는지 판단하고, 그제야 모델이 답을 만들고, 그 답을 다시 음성으로 합성해서 스피커로 내보냅니다. 이 과정이 매끄럽게 이어지지 않으면 대화는 곧바로 어색해집니다. 답이 너무 늦게 나오거나, 아직 말하고 있는데 에이전트가 끼어들거나 하는 식입니다.
이번 글에서는 LiveKit으로 음성 에이전트를 구성하면서 정리한 파이프라인의 전체 구조를 따라가 보려고 합니다. 한 번의 대화가 어떤 컴포넌트를 거쳐 처리되는지를 먼저 큰 그림으로 보고, STT, LLM, TTS, VAD 네 가지 핵심 컴포넌트가 각각 어떤 역할을 맡는지 살펴보겠습니다. 실제로 가장 까다로웠던 Turn-taking(대화 턴 전환) 의 세부, 그러니까 발화 종료를 어떻게 판정하고 끼어들기를 어떻게 처리하는지는 다음 글에서 따로 다루겠습니다.
Voice AI Agent은 한 번의 대화를 어떻게 처리할까
먼저 전체 그림입니다. 아래 다이어그램이 한 번의 대화가 흐르는 경로 전체를 담고 있습니다.
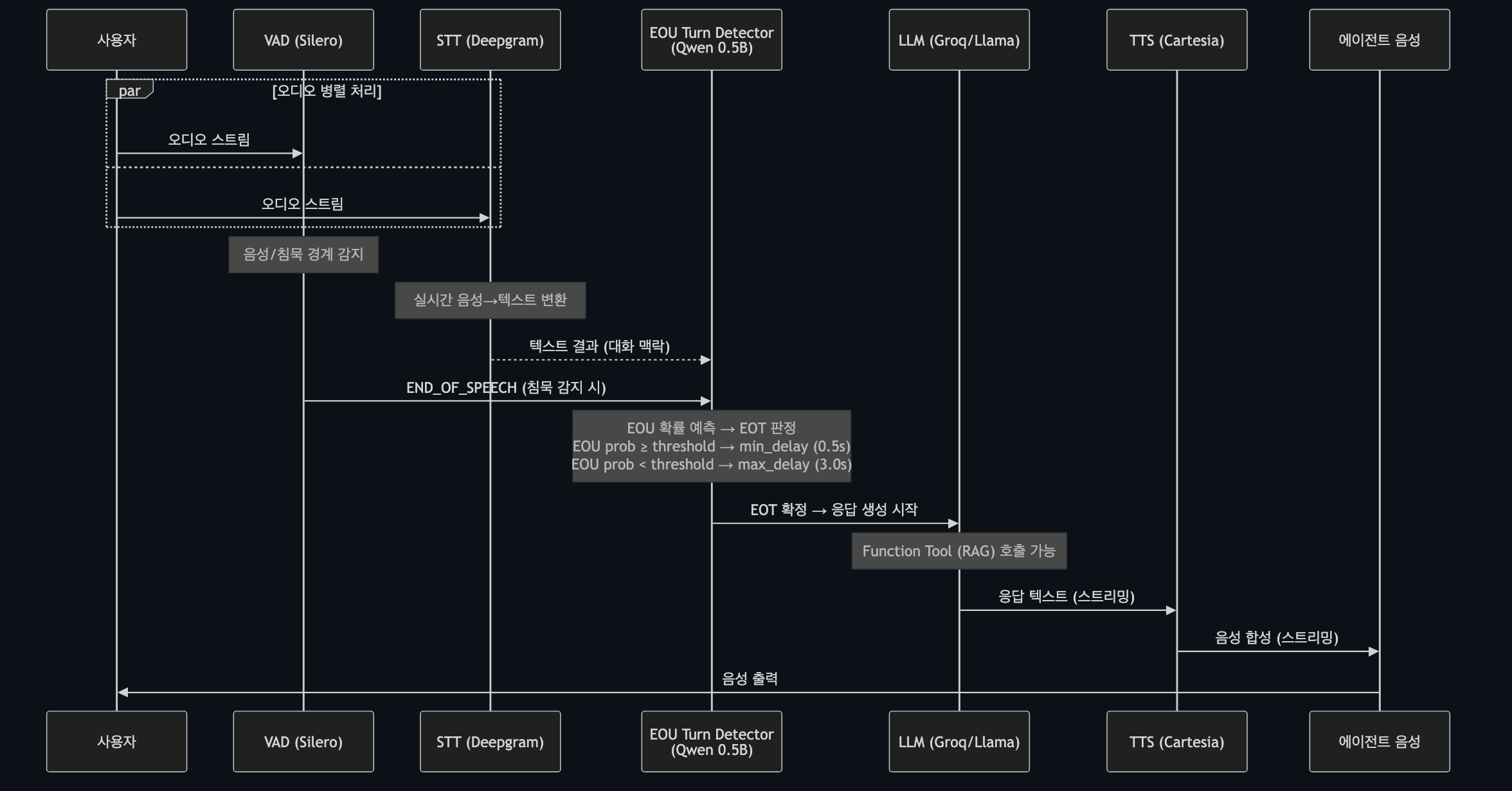
출처: LiveKit Agents 파이프라인 기반 정리
핵심만 추리면 이렇습니다. 사용자의 음성이 들어오면 그 오디오 스트림이 두 갈래로 동시에 흘러갑니다. 한쪽은 음성을 텍스트로 바꾸는 STT로, 다른 한쪽은 말소리와 침묵의 경계를 감지하는 VAD로 갑니다. 두 신호를 합쳐서 “사용자가 말을 끝냈는지”를 판정하고, 끝났다고 확정되면 그제야 LLM이 답을 만들기 시작합니다. 만들어진 답은 TTS가 음성으로 합성해 스피커로 내보냅니다.
이 흐름에서 한 가지 미리 짚어둘 점이 있습니다. STT와 VAD가 병렬로 동작하고, 에이전트가 답을 말하는 도중에도 이 둘은 계속 켜져 있다는 점입니다. 사용자가 언제든 다시 끼어들 수 있어야 하기 때문입니다. 이 부분이 바로 다음 글에서 다룰 Barge-in(끼어들기) 의 출발점입니다.
기본 파이프라인 따라가기
그럼 정상적인 한 턴이 어떻게 흘러가는지를 단계별로 따라가 보겠습니다.
- 사용자의 마이크 입력이 노이즈 캔슬링을 거쳐 오디오 스트림이 됩니다.
- 이 오디오 스트림이 VAD(예: Silero) 와 STT(예: Deepgram) 로 병렬 전송 됩니다.
- STT는 음성을 실시간으로 텍스트로 변환합니다.
- VAD는 음성과 침묵의 경계를 감지하고, 침묵이 감지되면
END_OF_SPEECH이벤트를 발생시킵니다. - EOU Turn Detector(예: Qwen 0.5B) 가 STT 텍스트(대화 맥락)와 VAD의 침묵 신호를 함께 입력받아, 발화가 정말 끝났을 확률(EOU 확률)을 예측합니다.
- 이 확률에 따라 얼마나 더 기다릴지(endpointing delay)가 갈립니다. 확률이 높으면 짧게(
min_endpointing_delay, 기본 0.5초), 낮으면 길게(max_endpointing_delay, 기본 3.0초) 대기합니다. - 대기하는 동안 추가 발화가 없으면 EOT(End of Turn, 턴 종료) 가 확정됩니다. 만약 사용자가 다시 말하기 시작하면 EOT 태스크를 취소하고 발화 처리로 되돌아갑니다.
- EOT가 확정되면 LLM(예: Gemini 2.5 Flash) 이 응답 텍스트를 스트리밍으로 생성합니다. 이때 Function Tool이나 RAG를 호출할 수 있습니다.
- TTS(예: Cartesia Sonic-3) 가 그 텍스트를 스트리밍 음성으로 합성해 스피커로 내보냅니다.
여기서 EOU 확률이나 endpointing delay 같은 표현이 낯설 수 있는데, 이 부분은 Turn-taking의 핵심이라 다음 글에서 충분히 풀어보겠습니다. 이번 글에서는 “VAD가 침묵을 감지하고, EOU Turn Detector가 맥락을 보고 한 번 더 판단해서 턴 종료를 확정한다” 정도의 큰 그림만 잡고 넘어가면 충분합니다.
컴포넌트 하나씩 살펴보기
이제 파이프라인을 구성하는 네 컴포넌트를 하나씩 보겠습니다. 이번 실험에서 실제로 사용한 모델도 함께 적어두겠습니다.
STT (Speech-to-Text, 음성 인식)
STT는 사용자의 음성 발화를 텍스트로 바꾸는 음성 인식 모델입니다. 이번 실험에서는 Deepgram 을 사용했습니다.
파이프라인 안에서 STT는 노이즈 캔슬링을 거친 오디오 스트림을 VAD와 병렬로 받습니다. 그리고 실시간 스트리밍 전사를 수행하는데, 여기서 중간 결과(interim)와 최종 결과(final)를 실시간으로 반환한다는 점이 중요합니다. 이렇게 변환된 텍스트는 두 군데에 쓰입니다. 하나는 EOU Turn Detector에 대화 맥락으로 전달되어 발화 종료 판정에 활용되고, 다른 하나는 EOT 확정 이후 LLM의 입력 쿼리로 사용되어 응답 생성에 쓰입니다.
LLM (Large Language Model, 대형 언어 모델)
LLM은 사용자 발화 텍스트를 입력받아 응답 텍스트를 생성하는 모델입니다. 이번 실험에서는 Gemini 2.5 Flash 를 사용했습니다.
LLM은 EOT가 확정되는 시점에 호출되어 응답을 만듭니다. 이때 대화 히스토리(ChatContext)를 기반으로 멀티턴 문맥을 유지합니다. 한 가지 눈여겨볼 점은 응답을 청크 단위로 스트리밍 출력 한다는 것입니다. 덕분에 TTS가 응답 전체가 완성되기를 기다리지 않고, 먼저 도착한 텍스트 조각부터 곧바로 음성 합성을 시작할 수 있습니다. 또한 Function Calling을 지원하는데, 이번 실험에서는 이를 FAQ 검색(RAG) 연동에 활용했습니다.

출처: 이번 실험 RAG 연동 구성 정리
TTS (Text-to-Speech, 음성 합성)
TTS는 LLM이 만든 응답 텍스트를 음성으로 합성해 사용자에게 들려주는 모델입니다. 이번 실험에서는 Cartesia Sonic-3 를 사용했습니다.
TTS의 핵심은 LLM이 보내는 스트리밍 텍스트 청크를 받는 즉시 점진적(incremental) 음성 합성 을 수행한다는 점입니다. 만약 모델이 네이티브 스트리밍을 지원하지 않으면, sentence tokenizer로 텍스트를 문장 단위로 잘라 점진적으로 합성합니다(LiveKit 공식 문서 기준). 그리고 사용자 체감 응답 속도를 좌우하는 지표가 TTFB(Time To First Byte), 즉 첫 음성 바이트가 출력되기까지의 시간입니다. 답의 전체 길이보다도, 첫 소리가 얼마나 빨리 나오기 시작하는지가 체감 응답 속도에 직결됩니다.
VAD (Voice Activity Detection, 음성 활동 감지)
VAD는 오디오 스트림을 짧은 프레임 단위로 모델에 통과시켜 각 구간의 음성 존재 확률(speech probability) 을 실시간으로 산출합니다. 이 확률이 임계값(threshold, 기본 0.5)을 넘으면 ‘발화 중’, 넘지 않는 구간이 일정 시간(silence_duration_ms) 이상 지속되면 ‘침묵(발화 종료)‘으로 판정합니다. 단순히 음량(데시벨)을 보는 게 아니라 학습된 모델로 음성 여부를 판단하기 때문에, 배경 소음과 실제 음성을 구분할 수 있습니다.
VAD는 음성 에이전트의 Turn-taking 관리에서 결정적인 역할을 합니다. VAD가 음성과 침묵의 물리적 경계를 감지하면, EOU Turn Detector가 대화 맥락을 바탕으로 발화 종료 여부를 한 번 더 판정합니다. 이 두 컴포넌트의 협업 덕분에 단순 침묵 기반보다 훨씬 자연스러운 턴 전환이 가능합니다. 이번 실험에서 실제로 쓴 구성은 다음과 같습니다.
- SileroVAD(CNN+LSTM 계열) 는 로컬 CPU에서 가볍게 추론합니다. 오디오 스트림에서 음성과 침묵 구간을 실시간으로 구분해
START_OF_SPEECH/END_OF_SPEECH이벤트를 발생시킵니다. - EOU Turn Detector (MultilingualModel) 는 Qwen2.5-0.5B 기반 경량 LLM으로, 로컬 ONNX 추론(100ms 내외)을 수행합니다. STT 텍스트(대화 맥락)와 VAD의 침묵 신호를 입력받아 EOU 확률을 예측하고, 이를 바탕으로 endpointing delay를 분기시켜 EOT를 확정합니다.
마무리
지금까지 Voice AI Agent이 한 번의 대화를 어떻게 처리하는지, 그 전체 파이프라인을 따라가 봤습니다. 정리하면 사용자의 음성이 STT와 VAD로 병렬로 갈라지고, 두 신호를 합쳐 발화 종료를 판정한 뒤, LLM이 답을 만들고 TTS가 음성으로 돌려주는 흐름이었습니다. 그리고 이 모든 과정에서 ‘스트리밍’과 ‘병렬’이 반복해서 등장했는데, 결국 사용자가 체감하는 응답 속도를 한 조각이라도 줄이기 위한 설계라는 생각이 들었습니다.
큰 그림은 이렇게 깔끔해 보이지만, 정작 직접 돌려보면 가장 손이 많이 가는 곳은 따로 있었습니다. 바로 “사용자가 말을 정말 끝냈는가”를 판정하는 Turn-taking 부분입니다. 특히 한국어 짧은 문장에서는 에이전트가 한참 침묵하다 뒤늦게 답하는 문제가 있었는데, 그 원인을 로그로 추적하고 파라미터를 튜닝했던 과정이 꽤 흥미로웠습니다. 다음 글에서는 이 Turn-taking과 Endpointing, 그리고 Barge-in 을 본격적으로 풀어보겠습니다.